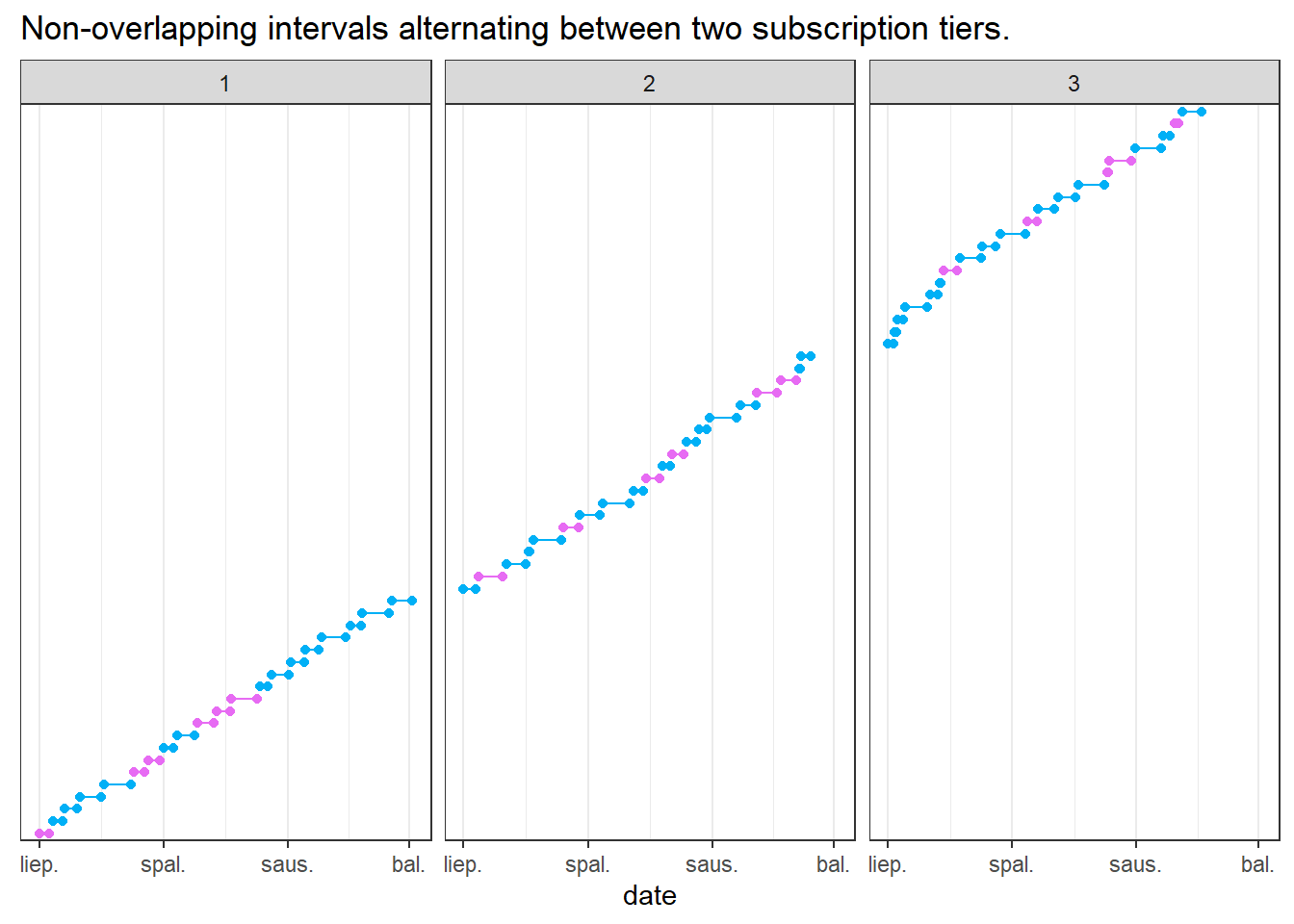
If you’re a data analyst at a company, it’s VERY likely your company stores some data as a Type 2 slowly-changing dimension. It’s also likely that the way it’s stored may not align with how you want to model it in the warehouse. Imagine you’re managing a subscription-based service. You might want to display a user’s subscription history as a single entry, showing the start date of their first subscription and the end date of their last - but only if there were no gaps in service. Or perhaps you’re tracking subscription tiers, and you want to combine multiple entries into one as long as the tier remained the same. In this post, we’ll explore how to handle these scenarios efficiently, making your data more manageable and insightful.
Also, as an aside, I’ve started this post as a “consecutive” date range blog post for cases where your rows are consecutive and gapless. But in reality, the island and gaps method is universal for any scenario where the date ranges are not overlapping.
Sample Data
Let’s follow along with the example I introduced just now: our sample data are consecutive date ranges that alternate between two subscription tiers (highlighted with a different color). Let’s also introduce small gaps between the date ranges - visually they’re not visible but the SQL query will pick up on them.
library(duckdb)
Loading required package: DBI
library(lubridate)
Attaching package: 'lubridate'
The following objects are masked from 'package:base':
date, intersect, setdiff, union
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
I’m interested in two scenarios. First, grouping these intervals by their tier if the intervals are consecutive. Second, I want to also group those intervals by tier as well as by whether they were uninterrupted. I’m not interested in JUST getting the start and end dates for each group - for that, a normal group by would suffice.
Grouping date ranges by group and tier
All of the queries will follow the same pattern:
First, we do a row_number() for our groups whose rows are chronological - essentially, we’re building an index for each of our groups;
Then, we create another row_number() column that uses the group variable as well as ALL the rest of the columns we want to group by
Finally, we group by the difference between the two columns. The idea is that if the first and the second row_numbers are increasing sequentally at the same rate, their difference will produce a constant value. What’s even better is that value will be unique within the scope of the columns we’re grouping by!
with tmp as (selectrow_number() over (partitionbygroup_idorderby date_from) as group_rank,row_number() over (partitionbygroup_id, tier orderby date_from) as tier_rank,group_id, tier, date_from, date_tofrom consecutive_dates)selectgroup_id, tier,min(date_from) as date_from,max(date_to) as date_tofrom tmpgroupbygroup_id, tier, (group_rank-tier_rank)
What if we also want to check whether the data ranges are uninterrupted, i.e. they have no gaps? We have to build a new variable that checks whether the current subscription followed immediately after the one before it (through lag(date_to,1)). Then, we have to partition by that new column but we have to create a combined column from tier and the new column is_consecutive.
with lag_date_from as (select consecutive_dates.*,lag(date_to,1) over (partitionbygroup_idorderby date_from) as lag_date_tofrom consecutive_dates),gap_calc as (select lag_date_from.*,casewhen lag_date_to +interval1day= date_from then1else0endas is_consecutivefrom lag_date_from),tmp as (selectrow_number() over (partitionbygroup_idorderby date_from) as group_rank,row_number() over (partitionbygroup_id, tier orderby date_from) as group_tier_rank,row_number() over (partitionbygroup_id, tier||cast(is_consecutive asvarchar) orderby date_from) as group_tier_cons_rank, tier||cast(is_consecutive asvarchar) as tier_cons,group_id, is_consecutive, tier, date_from, date_tofrom gap_calc)selectgroup_id, tier_cons,min(date_from) as date_from,max(date_to) as date_tofrom tmpgroupbygroup_id, tier_cons, (group_rank-group_tier_cons_rank)
It was! I don’t mind, though - it’s there to visually prove the query works. The query is extensible to other scenarios. For example, if you had a task of grouping user events into sessions if the events happened within 3 days of each other, you could just change the case when statement that creates the is_consecutive column so that we check whether lag(date_to,1) + interval 3 day is equal to or larger than date_from. Feel free to try the pattern out yourself!